Insee - Taux d’activité
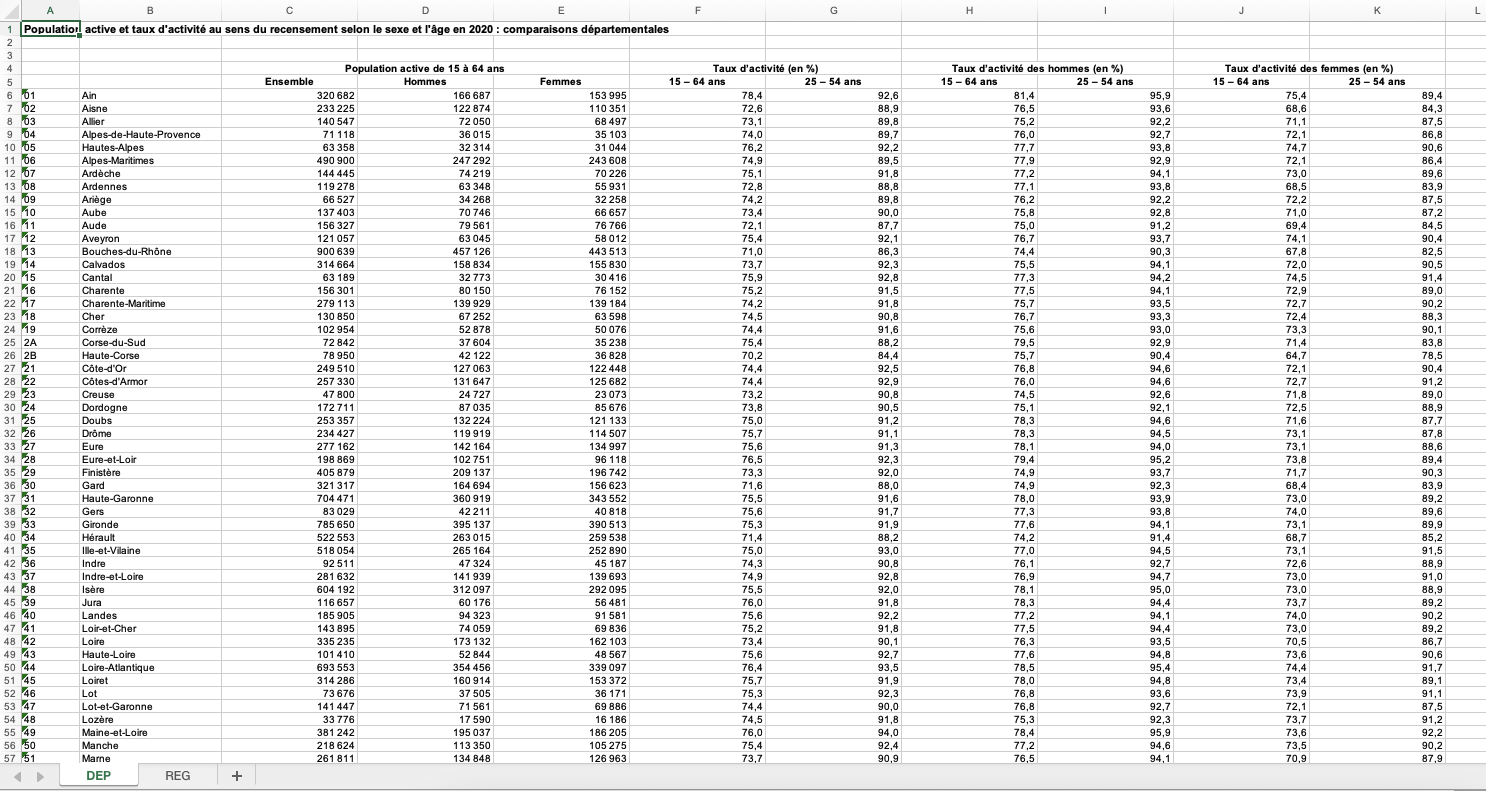
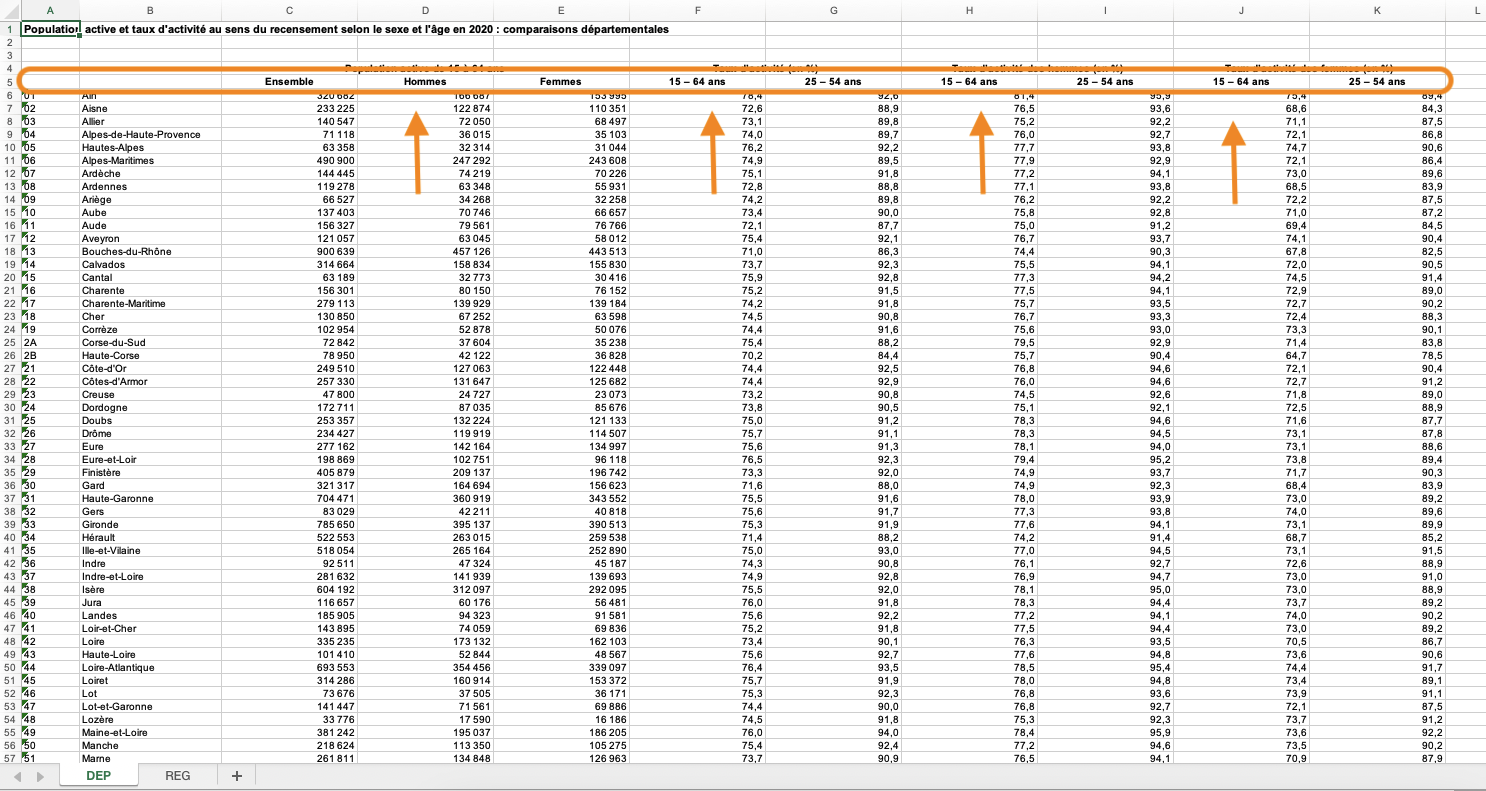
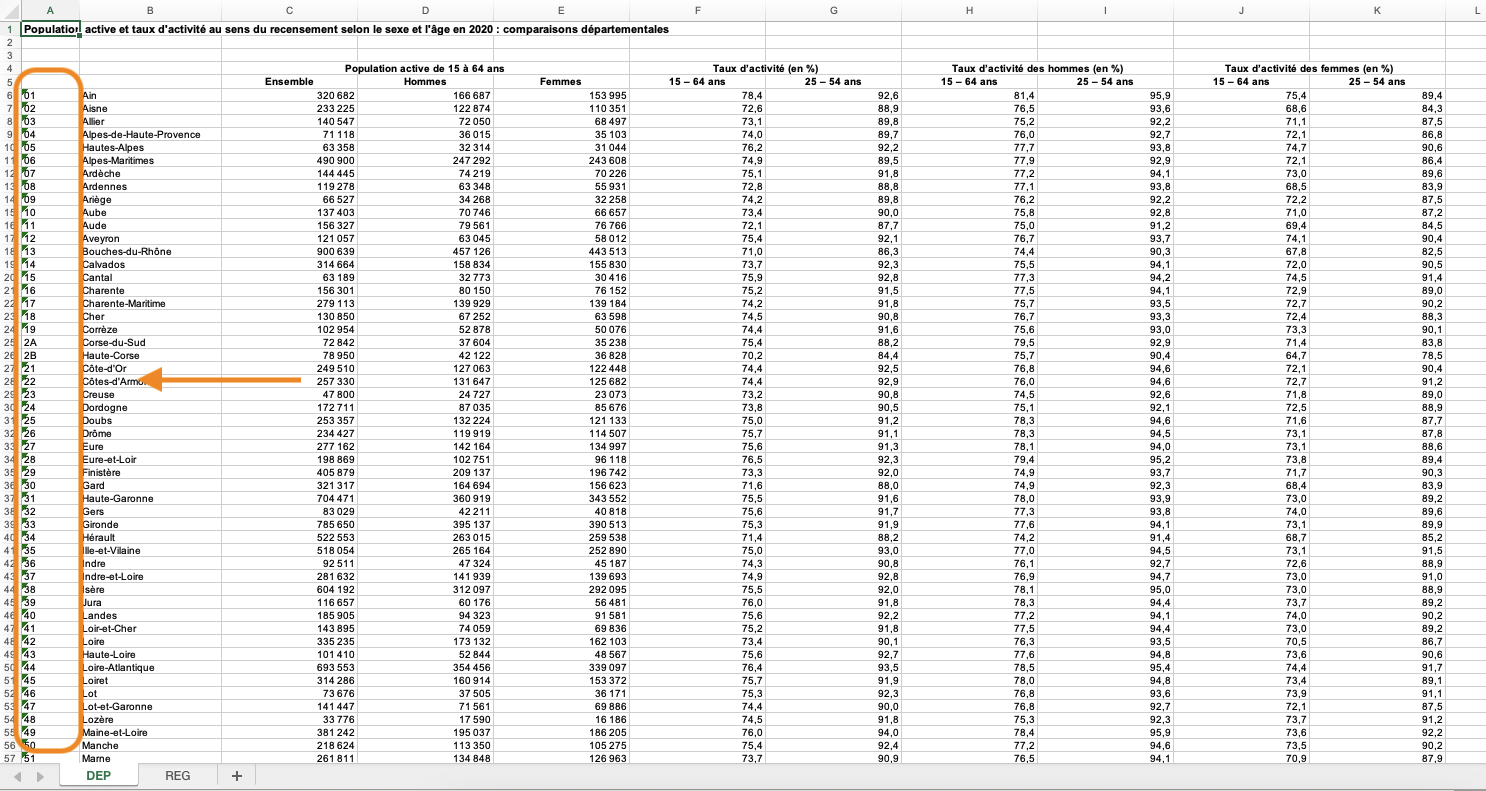
Population active et taux d’activité au sens du recensement selon le sexe et l’âge en 2020 : comparaisons départementales
<- "data/TCRD_015.xlsx"
Insee - Taux d’activité
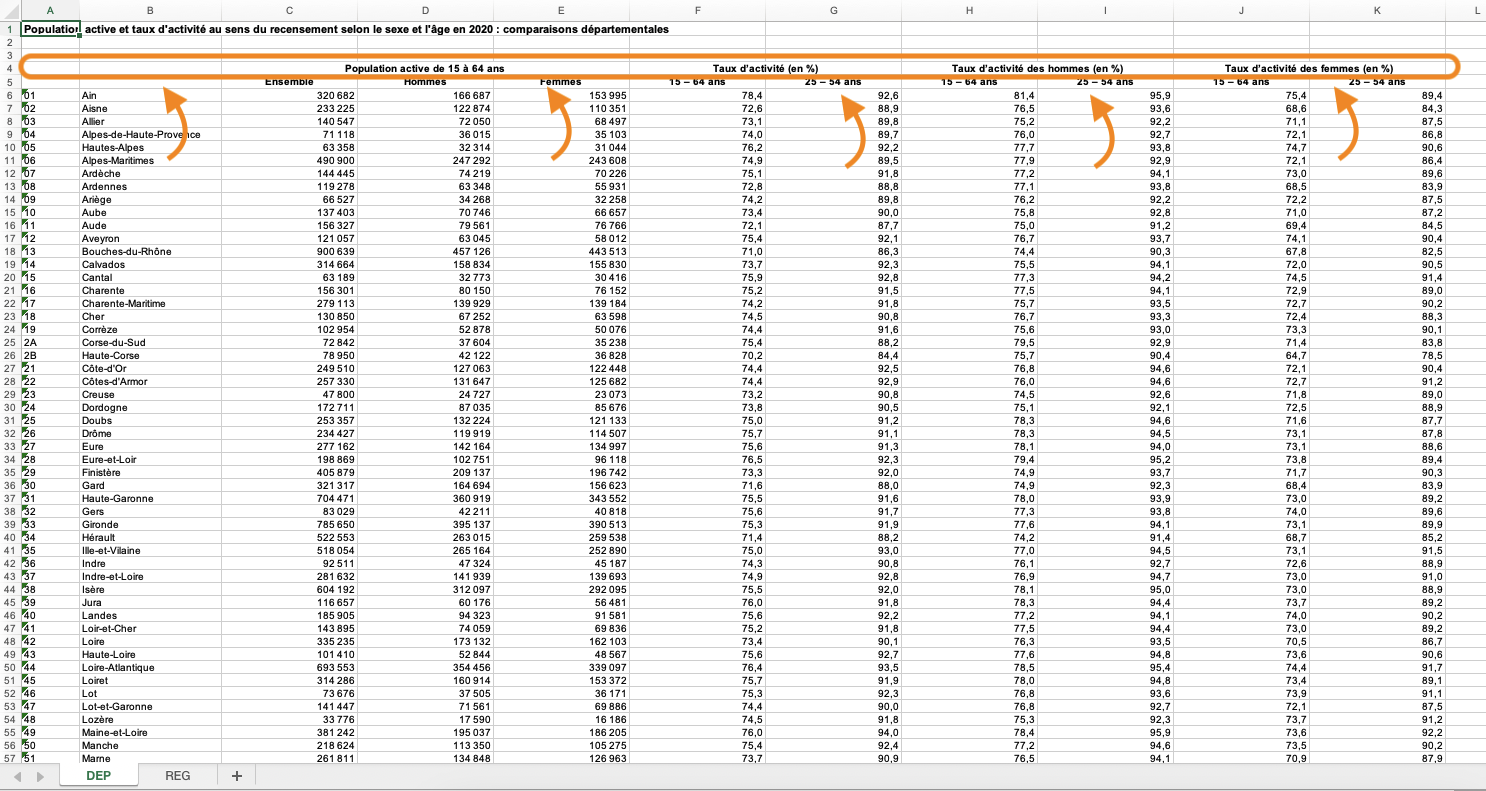
Intitulés des colonnes fusionnées
Insee - Taux d’activité
Zone des données décalée
Insee - Taux d’activité - readxl
En spécifiant les colonnes à la main
read_xlsx (sheet = "DEP" ,skip = 5 ,col_names = c ("code_dep" ,"lib_dep" ,"pop_active_tot" ,"pop_activite_h" ,"pop_active_f" ,"tx_act_15_64" ,"tx_act_25_54" ,"tx_act_h_15_64" ,"tx_act_h_25_54" ,"tx_act_f_15_64" ,"tx_act_f_25_54"
Insee - Taux d’activité - readxl
Insee - Taux d’activité - tidyxl
xlsx_cells donne un tibble de la localisation et du contenu des cellules
xlsx_cells (path_insee_activite)
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 )
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 ) |> behead ("up-left" , "typ_var" )
up-left car une cellule fusionnée ne remplit que le haut à gauche
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 ) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" )
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 ) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" )
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 ) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" ) |> behead ("left" , "lib_dep" )
Insee - Taux d’activité - tidyxl + unpivotr
xlsx_cells (path_insee_activite) |> filter (sheet == "DEP" & row >= 3 ) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" ) |> behead ("left" , "lib_dep" ) |> select (typ_var, mod_var, code_dep, lib_dep, numeric)
Drees - ISD C24
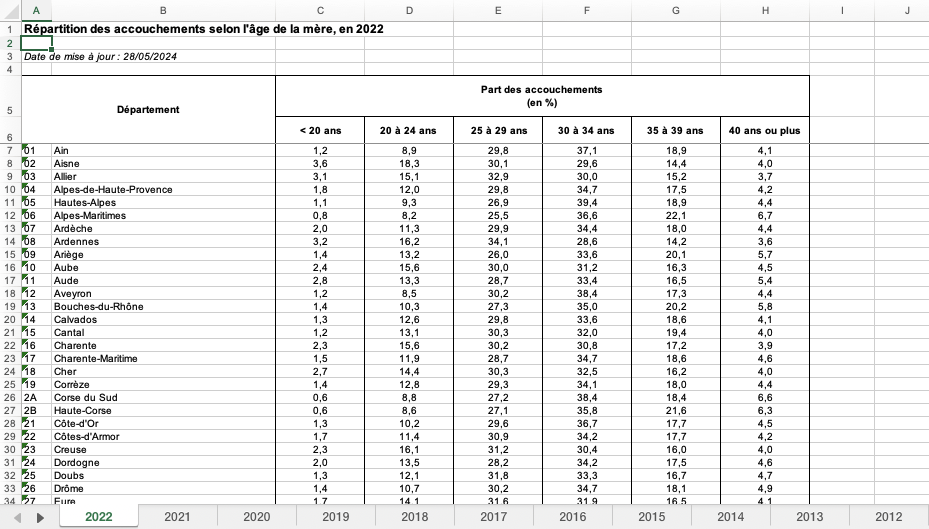
Répartition des naissances par âge de la mère
<- "data/C24-ISD_Part_accouchements_selon_age_mere.xlsx"
Drees - ISD C24
Début des données décalées
Drees - ISD C24
Intitulés des colonnes fusionnées
Drees - ISD C24
Un onglet par année (mais tous pareil) + un onglet de documentation
Drees - ISD C24
Des données à la fin que l’on ne souhaite pas importer
Drees - ISD C24 - readxl
On prend les colonnes telles quelles
read_xlsx (path_c24,sheet = "2022" ,skip = 5 ,.name_repair = "unique_quiet" ) |> rename (code_dep = ...1 ,lib_dep = ...2 ) |> pivot_longer (- c (code_dep, lib_dep),names_to = "age_mere" ,values_to = "perc_naiss" )
Drees - ISD C24 - readxl
Idem sur les onglets dans un map
excel_sheets (path_c24) |> set_names () |> - 12 ] |> map (read_xlsx,path = path_c24,skip = 5 ,.name_repair = "unique_quiet" ) |> list_rbind (names_to = "annee" ) |> rename (code_dep = ...1 ,lib_dep = ...2 ) |> pivot_longer (- c (annee, code_dep, lib_dep),names_to = "age_mere" ,values_to = "perc_naiss" ) |> mutate (annee = as.numeric (annee)) |> filter (! is.na (code_dep) & ! is.na (perc_naiss) & ! code_dep %in% c ("F" , "M" ))
Drees - ISD C24 - tidyxl
<- xlsx_cells (path_c24)
Drees - ISD C24 - tidyxl + dplyr/tidyr
|> filter (sheet != "Documentation" ) |> filter (row >= 4 & ! is_blank & col != 2 ) |> select (sheet, row, col, character, numeric) |> mutate (header_row = case_when (row == 6 ~ character),code_dep = case_when (col == 1 ~ coalesce (as.character (numeric), character))) |> group_by (col) |> fill (header_row, .direction = "down" ) |> group_by (row) |> fill (code_dep, .direction = "down" ) |> ungroup () |> filter (! is.na (numeric) & ! is.na (code_dep) & ! is.na (header_row) & ! code_dep %in% c ("F" , "M" )) |> mutate (sheet = as.numeric (sheet),header_row = str_trim (header_row)) |> select (annee = sheet,age_mere = header_row,perc_naiss = numeric)
Drees - ISD C24 - tidyxl + unpivotr
|> filter (row >= 5 ) |> group_by (sheet) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" ) |> behead ("left" , "lib_dep" ) |> ungroup () |> mutate (mod_var = str_trim (mod_var)) |> select (sheet, typ_var, mod_var, code_dep, lib_dep, numeric) |> filter (! is.na (code_dep) & ! code_dep %in% c ("F" , "M" ) & ! is.na (numeric))
Drees - ISD C24 - tidyxl + unpivotr
Astuces
on peut modifier le nombre de lignes à sauter par onglet (dans le filter), car les espacements ne sont pas toujours les mêmes d’une année sur l’autre
utiliser les fonctions de dplyr et tidyr comme fill ou coalesce en complément
on peut aussi appliquer à plusieurs fichiers Excel si les formats sont identiques
Astuces
récupérer d’autres informations avec str_detect, comme la date de mise à jour
|> select (sheet, character) |> filter (str_detect (character, "mise à jour" )) |> mutate (date_maj = str_remove (character, "Date de mise à jour : " ),date_maj = dmy (date_maj)
Résultat, avec Observable
Drees - FAJ série
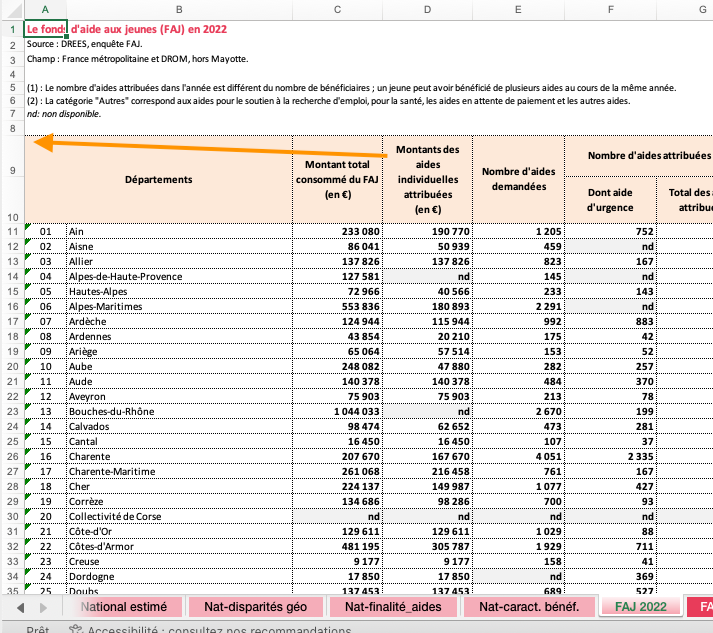
Fond d’aide aux jeunes
Et des espacements différents, à détecter
Drees - FAJ série
<- xlsx_cells ("data/FAJ Données annuelles 2007-2022.xlsx" ) |> filter (str_sub (sheet, 1 , 6 ) == "FAJ 20" & sheet != "FAJ 2015" )
Ligne de début - “Départements”
<- df_cells_faj |> filter (character == "Départements" ) |> select (sheet, row_min = row)
Ligne de fin - ligne blanche vide
<- df_cells_faj |> filter (is_blank & col == 1 ) |> inner_join (df_cells_faj_min, by = join_by (sheet)) |> filter (row > row_min + 3 ) |> group_by (sheet) |> filter (row == min (row)) |> ungroup () |> select (sheet, row_max = row) |> mutate (row_max = row_max - 1 )
Drees - FAJ série
|> inner_join (df_cells_faj_min, by = join_by (sheet)) |> inner_join (df_cells_faj_max, by = join_by (sheet)) |> filter (between (row, row_min, row_max)) |> group_by (sheet) |> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" ) |> behead ("left" , "lib_dep" ) |> ungroup () |> select (sheet, typ_var, mod_var, code_dep, lib_dep, character, numeric)
Drees - FAJ 2022
Deux tableaux dans le même onglet
<- df_cells_faj |> filter (sheet == "FAJ 2022" & row >= 9 )
Drees - FAJ 2022
Détection des débuts de tableaux
<- df_cells_faj_filtered |> filter (character %in% c ("Départements" , "Métropoles et départements hors métropoles" ))
Partition ~ sorte de nest
<- partition (df_cells_faj_filtered,
Drees - FAJ 2022
Puis map (ou traitement séparé)
map ($ cells,|> behead ("up-left" , "typ_var" ) |> behead ("up" , "mod_var" ) |> behead ("left" , "code_dep" ) |> behead ("left" , "lib_dep" ) |> select (typ_var, mod_var, code_dep, lib_dep, character, numeric)|> set_names ("dep" , "metro" ) |> list_rbind (names_to = "type_geo" )
Drees - Panorama statistique
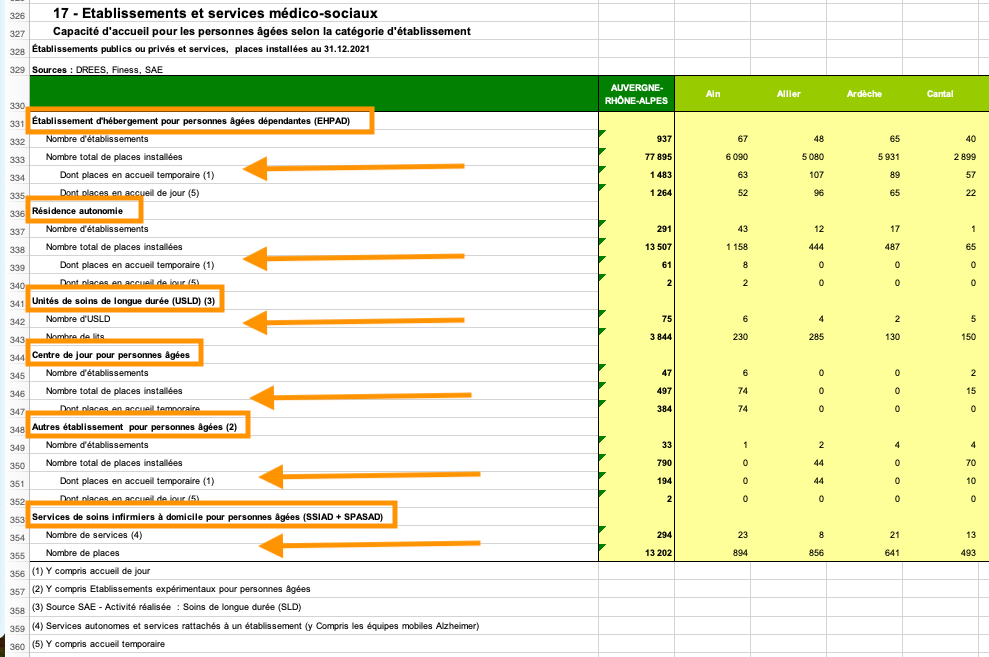
Etablissements pour personnes âgées, tableau 17
Drees - Panorama statistique
De l’information stockée sous une autre forme que le test :
Drees - Panorama statistique
Chargement du contenu et du format de chaque cellule
<- "data/PanoFrance2022.xlsx" <- xlsx_cells (path_panorama) |> filter (between (row, 330 , 355 ))<- xlsx_formats (path_panorama)
Drees - Panorama statistique
On utilise unpivotr::behead_if
|> behead ("up" , "code_geo" ) |> behead_if (format_panorama$ local$ font$ bold[local_format_id],direction = "left-up" ,name = "type_etab" ) |> behead_if ($ local$ alignment$ indent[local_format_id] == 2 ,direction = "left-up" ,name = "type_var" |> behead_if ($ local$ alignment$ indent[local_format_id] == 4 ,direction = "left" ,name = "type_places" |> select (code_geo, type_etab, type_var, type_places, numeric, character) |> filter (! is.na (numeric))
Drees - Panorama statistique